
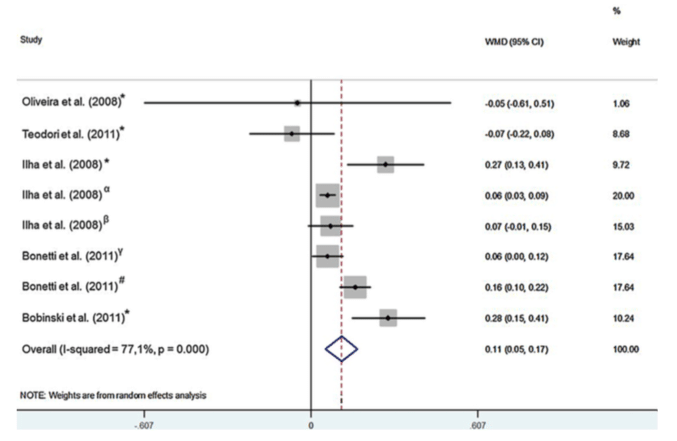
মেটাঅ্যানালাইসিসকে বলা হয় স্বাস্থ্য গবেষণার সর্বচ্চো প্রমাণ। কারণ, কোন একটি নির্দিষ্ট প্রশ্নের উত্তর খুঁজতে গিয়ে করা গবেষণাগুলোর প্রাপ্ত ফলাফলকে একত্র করে হিসেব প্রকাশ করাই হল মেটাঅ্যানালাইসিস।
কিন্তু, বিভিন্ন গবেষণায় প্রাপ্ত হিসেবকে একত্র করার বিষয়টি সরল অংকের মত সহজ নয়। অর্থাৎ, কিছু গবেষণাপত্র একত্র করে সংশ্লিষ্ট হিসেব নিকেষ শুধু যোগ করে ভাগ করলেই যে একটি একত্রিত হিসেব পাওয়া যাবে তা নয়। মেটাঅ্যানালাইসিসে কোন কোন গবেষণাকে অন্তর্ভূক্ত করা হবে তা নির্ভর করে অনেকগুলো প্রশ্নের উপর এবং কিছু পূর্ব নির্ধারিত যোগ্যতার আলোকে গবেষণাপত্র নির্বাচন করতে হয়। আলোচ্য প্রবন্ধে আমরা মেটাঅ্যানালাইসিসে যে প্রক্রিয়াসমূহের মাধ্যমে হিসেবগুলোকে একত্রিত করা হয় তার অন্যতম একটি প্রক্রিয়া সম্পর্কে সহজভাবে বোঝার চেষ্টা চালাবো। জানি না কি হয়! চলুন নেমে পড়ি।
একটি উদাহরণ দিয়ে বিষয়টি বুঝার চেষ্টা করি। মনে করুন আপনি বাংলাদেশের প্রাপ্তবয়স্ক মানুষের রক্তের সুগারের গড় হিসেব বের করতে চান। আমরা জানি প্রতিটি গবেষণায় কিছু স্যাম্পল নিয়ে কাজ করে। যেহেতু একটি স্থানে বিভিন্ন ধরনের মানুষ থাকে সেহেতু উক্ত স্থানে কৃত গবেষণায় আমরা রক্তের সুগারের একটি মিন (তথা গড়) এবং ভ্যারিয়েন্স (তথা ভেদমান) পাব। আবার বিভিন্ন স্থানেকৃত গবেষণায় বিভিন্ন মিন এবং ভ্যারিয়েন্স পাওয়া যাবে।
ধরি, আপনি একটি মেটাঅ্যানালাইসিস করছেন যেখানে আপনি ঢাকা, চট্টগ্রাম, সিলেট, রাজশাহীতে করা পৃথক কিছু গবেষণাপত্র সিলেক্ট করেছেন। যেগুলোতে উক্ত স্থানে বসবাসরত মানুষের রক্তের সুগারের গড় দেয়া আছে। উক্ত গবেষণাপত্রে সংশ্লিষ্ট শহরের সব মানুষকে নিয়ে রক্তের সুগার মাপা হয়নি। বরং, প্রতিটি শহর থেকে কিছু স্যাম্পল মানুষ নিয়ে গবেষণা করা হয়েছে।
ফলে উক্ত চারটি গবেষণা পত্রে চার রকম মিন (গড়) এবং তদসংশ্লিষ্ট চার রকম ভ্যারিয়েন্স দেয়া আছে। বোঝার সুবিদার্থে ধরে নেই মিন এবং ভ্যারিয়েন্স যথাক্রমে –
মিন – ৪, ৫, ৬ ও ৭ …… (১)
ভ্যারিয়েন্স – ২.২৫, ৩.০৬, ৪.০০ ও ১.৫৬ ……. (২)
অর্থাৎ, দেখা যাচ্ছে চারটি জায়গার স্টাডিতে মিন ও ভ্যারিয়েন্স ভিন্ন।
পরবর্তী আলোচনায় যাবার আগে আসুন ভ্যারিয়েন্স সম্পর্কে একটি ইনটুইটিভ ফিল নেয়ার চেষ্টা করি। সহজ কথায় ভ্যারিয়েন্স হল একটি স্টাডিতে যে ‘স্যাম্পল’ ব্যক্তিদের নেয়া হয়েছে তাদের ব্লাডসুগার উক্ত স্যাম্পলের মিন থেকে কতটুকু দূরে অবস্থান করছে। একটু গভীর ভাবে ভাবলে বুঝা যাবে, যে একটি এলাকায় থেকে যতবেশী মানুষকে স্যাম্পল হিসেবে নেয়া যাবে ঐ স্যাম্পলের ভ্যারিয়েন্স তত কমে আসবে। এটা অবশ্য সমীকরণ থেকে সবচেয়ে ভাল বুঝা যায়-
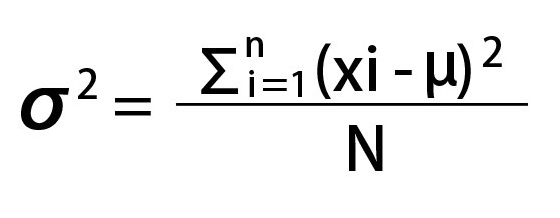
সমীকরণে স্যাম্পল সাইজ ‘N’ যেহেতু ভগ্নাংশের নিচে (ডিনোমিনেটরে) আছে সেহেতু এটি যত বড় হবে ভ্যারিয়েন্স তত ছোট হবে।
সুতরাং ভ্যারিয়েন্স থেকে আপনি একসাথে দুটো তথ্য পাবেন। এক, কোন স্টাডির স্যাম্পল সাইজ কত এবং, দুই, কোন স্টাডির সংশ্লিষ্ট ভ্যারিয়েবলের ভ্যারিয়েশন কেমন।
আরেকটি বিষয় হল, একটি স্টাডির স্যাম্পল সাইজ যত বড় হবে সে স্টাডি তত ভালভাবে পপুলেশনের প্রতিনিধিত্ব করতে পারবে। ধরুন আপনি এক এলাকার ১০০০০ জনের মধ্যে গবেষণা করতে চান। তাহলে তাদের মধ্য থেকে ১০০ জনকে স্যাম্পল হিসেবে নিলে পপুলেশনের সত্যিকারের হিসেবে জানতে পারবেন নাকি ১০০০ জনকে নিলে? অবশ্যই ১০০০ জনকে নিলে। (অবশ্য খরচ বেশী হওয়ার কারণে হয়ত ১০০০ জনকে নিয়ে করা অনেক সময় অবাস্তব হতে পারে। সেটা ভিন্ন আলোচনা।)
এখন আপনি যেহেতু মেটাঅ্যানালাইসিস করছেন, আপনার রিসার্চের জন্য নির্বাচিত স্টাডিগুলোকে আপনি সমান গুরুত্ব দিবেন না। কারণ, যে স্টাডি অল্প স্যাম্পল সাইজ নিয়ে করা তাদের তুলনায় যেটি বেশী স্যাম্পল নিয়ে করা তাদের চেয়ে হিসেবের দিকে দিয়ে দুর্বল। কেন দুর্বল? উপরের প্যারাটি আবার পড়ুন। অধিকন্তু, যে স্টাডিতে ভ্যারিয়েন্স বেশী সে স্টাডির মানুষজনের মধ্যে বিভিন্নতা বেশী। তাই আপনার ইচ্ছে থাকবে প্রতিটি স্টাডি থেকে হিসেব কালেক্ট করার সময় স্টাডিগুলোকে আলাদাভাবে গুরুত্ব দেয়া। বিজ্ঞানের জার্গন-এ এটাকে বলে ‘ওয়েইট’ দেয়া।
কেমন হয় যদি যে স্টাডিকে আমি নির্বাচন করেছি সেটা থেকেই কোন হিসেব নিয়ে ওয়েইট দেয়া যায়? ইন ফ্যাক্ট স্টাটিস্টিক্যাল হিসেব নিকেশের জন্য এ পথের বিকল্পও নেই।
তো ওয়েইট দেয়ার জন্য গবেষকরা যেই পদ্ধতি বের করেছেন ঐটার নাম হল ‘ইনভার্স ভ্যারিয়েন্স’ মেথড। নাম থেকেই বুঝতে পারছেন এখানে সিম্পলি ভ্যারিয়েন্সকে উল্টে দেয়া হবে।
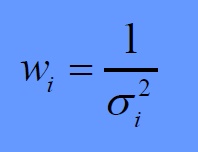
ভ্যারিয়েন্সকে উল্টে দিলে কি হবে? ওয়েল, ভ্যারিয়েন্স যত ছোট হবে ওয়েইট তত বড় হবে। আবার ভ্যারিয়েন্স যত বড় হবে ওয়েইট তত ছোট হবে। সুতরাং, যে স্টাডি বেশী মানুষ নিয়ে করেছে তাকে আমি বেশী গুরুত্ব দিলাম, আর যে স্টাডি কম মানুষ নিয়ে করেছে তাকে কম গুরুত্ব দিলাম।
মনে আছে তো আমরা সারাদেশের ব্লাড সুগারের একটা মিন (এসটিমেট) বের করতে চাই? এ কারণেই মেটাঅ্যানালাইসিস করছি। ওয়েইট বের করার পড় যে ফরমুলা দিয়ে আপনি (ওইয়েটেড মিন) বির করবেন সেটা হল-
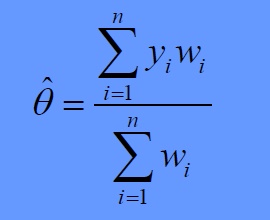
সমীকরণ নিয়ে ভেবে মাথা গণ্ডগোল না করে আসুন প্র্যাকটিক্যাল দেখি এটার ফল কি হল। আমরা উপরে (১) নং-এ যে মিন গুলো পেয়েছি ঐ চারটি মানকে যদি যোগ করে এভারেজ করি আসবে,
এভারেজ = (৪+৫+৬+৭)/৪=৫.৫
এখন যদি ওয়েটেড এভারেজ বা থিটা (θ) বের করি আসবে,
θ = ৫.৬৫ (জটিলতা নিরসনে ক্যালকুলেশনের দর্শণ পরিহার করা হল)
সুতরাং, দেখতে পারছেন ওয়েইট দেয়ার ফলে একটা পার্থক্য পাওয়া গেল। এখন আমরা আমরা যদি ঢাকা, চট্টগ্রাম, সিলেট এবং রাজশাহীর সমস্ত মানুষকে (পপুলেশন) নিয়ে একটি স্টাডি করতে পারতাম তাহলে প্রকৃত এভারেজ ব্লাডসুগার-এর যে মানটি পেতাম আমাদের এই হিসেবকৃত (এস্টিমেটেড) এভারেজ ব্লাডসুগার হয়ত তার কাছাকাছি হবে।
ধরে নিন আমি আপনাকে এরকম একটা মেটাঅ্যানালাইসিস করে আপনার সামনে বললাম যে এভারেজ ব্লাড সুগার হল ৫.৬৫ মিলিমোল/ডেসিলিটার। কিন্তু, আপনি তো চালাক মানুষ। আপনি এই হিসেব মানতে নারাজ। আপনি অভিযোগ করলেন যে আমি প্রতিটা স্টাডি থেকে মিন ব্লাগ সুগারের হিসেব নেয়ার সময় ধরে নিয়েছি যে তারা সবাই পপুলেশনের ব্লাড সুগার ৫.৬৫ (ধরে নেই এটাই আসল পপুলেশন ব্লাড সুগার এভারেজ) মাপার চেষ্টা করেছে। কিন্তু, বাস্তবে তা নাও হতে পারে। হতে পারে যে রাজশাহীর সকল মানুষের এভারেজ ব্লাড সুগার সিলেটের সকল মানুষের তুলনায় আসলেই ভিন্ন।
আচ্ছা আরেকটু ভেঙ্গে বলি। একটু ভেবে দেখুন সবাই আসলে কি করার চেষ্টা করছে। রাজশাহীর গবেষকরা চেষ্টা করেছে যে রাজশাহী অঞ্চলের মানুষের প্রকৃত ব্লাগ সুগারের একটা ধারণা পাওয়ার জন্য, উক্ত অঞ্চলের ‘সকল’ মানুষ থেকে ‘কিছু’ মানুষকে স্যাম্পল হিসেবে নিয়ে, প্রকৃত ব্লাড সুগারের একটা কাছাকাছি হিসেবে দিতে (সাধারণত ৯৫% শতাংশ আত্মবিশ্বাসের সাথে)। একই কাজ করেছে সিলেট, চট্টগ্রাম ও ঢাকার গবেষকরা।
অথচ, আমি যখন সবার হিসেব একত্র করার জন্য নির্বাচন করেছি, তখন ধরে নিয়েছি (তথা এসাম্পশন করে নিয়েছি) যে সবাই আসলে এই চার এলাকার সকল মানুষের সত্যিকারের এভারেজ ব্লাড সুগারের কাছকাছি একটা হিসেব দেয়ার চেস্টা করেছে।
এইটাকে স্ট্যাটিস্টিক্সে-এর জার্গনে বলা হয় ‘ফিক্সড ইফেক্ট মডেল’।
কিন্তু, আপনি যে অভিযোগ করেছেন তা সত্য হওয়া সমূহ সম্ভাবনা আছে। তার মানে এই চার এলাকায় ‘আসল’ বা ‘প্রকৃত’ বা ‘পপুলেশন’ এভারেজ হয়ত ভিন্ন। ফলে তারা হয়ত সবাই ভিন্ন লক্ষ্যমাত্রার কাছাকাছি হিসেব দিতে ব্যাস্ত। তাহলে তো আমাকে এই যে ভিন্নতা, হিসেব করার সময় সেটা আমলে নিতে হত, তাই না?
এই ভিন্নতা আমলে নেয়ার বিষয়কে বলে ‘র্যানডম ইফেক্ট মডেল’। র্যানডম ইফেক্ট মডেলে কিভাবে এই ভিন্নতাকে হিসেবের মধ্যে গনিতের ম্যাজিক দিয়ে ঢুকিয়ে দেয়া হয় সেটা আমরা অন্য কোন পোস্টে আলোচনা করব ইন শা আল্লাহ।
আজকে এই পর্যন্তই।
…….
পরিশিস্ট:
এই আলোচনা অবতারণার উদ্দেশ্য হল মেটাঅ্যানলাইসিসের ওয়েটিং-এর বিষয়টাকে একটা সহজাত অনুভূতিতে নিয়ে আসার চেষ্টা করা। এজন্য গনিত ও দুর্বোধ্য জারগনকে যতটা সম্ভব দূরে রাখার চেষ্টা করেছি।
আমরা যে ‘মিন ব্লাড সুগারের’ হিসেবগুলো ধার নিলাম। এগুলোকে একটি সরল কিন্তু জটিল নাম দেয়া হয়েছে। এটাকে বলে ‘ইফেক্ট সাইজ’। যেহেতু একেক স্টাডি একেক জিনিস হিসেব নিকেষ করে সেহেতু বিদ্যানরা হিসেবের লক্ষ্যবস্তুর নাম দিয়েছেন ‘ইফেক্ট সাইজ’। ফিক্সড ইফেক্ট ও র্যানডম ইফেক্ট মডেলের ‘ইফেক্ট’ শব্দটা এখান থেকেই এসেছে। (মাঝে মাঝে বিজ্ঞানকে দূর্বোধ্য করার জন্য বিদ্যানদের চেষ্টা দেখলে মাথার চুল ছিড়তে ইচ্ছে করে। হা হা! ডোন্টমাইণ্ড।)
আমি নিজেই যেহেতু শিক্ষানবিশ সেহেতু আমার আরেকটা উদ্দেশ্য হল আমার নিজের বোঝায় ভুল থাকলে শুধরে নেয়া। কেউ না কেউ তো তার মন্তব্য দিয়ে শুধরে দিবেন।
(হে! কারও সঙ্গে আলোচনা না করে লিখে শিখতে আসছে!)
আলোচনা কি বেশী সিলি হয়ে গেল? হলে জানাবেন প্লিজ।
সবশেষে, কষ্ট করে পড়ার জন্য একটা ধন্যবাদতো আপনি অবশ্যই পান। বুঝুন বা না বুঝুন। ধন্যবাদ!